TOPlist – zákulisí
Publikováno 21. srpna 2005 • 3 min. čtení • 619 slovJak je asi každému jasné, že srdcem podobného systému bude databáze a proto nejdřív budu psát o ní.
Jelikož zastávám přesvědčení, že se nemá ztrácet čas s tím, co udělali jiní a lépe, je použitá klasická relační databáze. Nejdřív MS SQL (proto také ty historické koncovky .asp), nyní když je TOPlist LAMP (je hezké, že se dá zkratka použít pro Perl i Python, ještě by to chtělo nějaký jazyk P a P-shell), používám MySQL. Zatím ve verzi 4.0 a přemýšlím, jestli použít 4.1 nebo počkat až na 5.0. Pro zajímavost jsem vytáhl graf zátěže. Zelená čára je aktuální počet dotazů za vteřinu a modrá je průměr od startu.
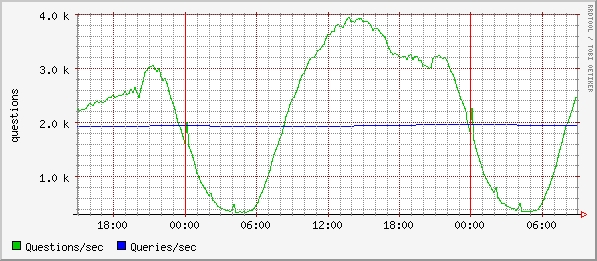
Pochopitelně, v případě že se jedná o zatíženější aplikaci (mimochodem, minulé pondělí, ze kdy je ten graf, byla poprvé překonána hranice 60 miliónů měření za den, běžně je nad 55 miliónů) je potřeba pečlivý návrh a trochu se věnovat nastavení. Ovšem, i příslušný hardware.
Na TOPlistu mi databáze běží na IBM xSeries 345. V konfiguraci 2xXeon 3GHz, 2 GB RAM a 3+1 36GB (proč plus jedna bude dál) disky. Jedná se o rackový server velikosti 2U. Tradičně výborně je řešené uchycení. Lyžiny se nasazují tím, že se natáhnou západky, které se pak „nastřelí“ do lišt ve skříni. A server se pak už jen na ně položí a zajistí. Takže žádné šroubování deseti šroubků a hledání zapadlých mezi kabeláží, ale s trochou cviku je za dvě minuty všechno vyřízeno. Jediný zádrhel může nastat s délkou. Většina hostingů má skříně pouze 80cm hluboké. A vzhledem k délce 70cm a prostoru potřebného k proudění chladícího vzduchu je potřeba použít skříň alespoň s metrovou hloubkou.
Na serverovně jsem ho zkusil vyfotit na mobilu. Když jsem to viděl, tak jsem si říkal, že tam někdy musím vzít digiták. Ale nakonec jsem se rozhodl pro tuhle, protože je taková autentická („Proč jsou vždycky záběry UFO rozmazaný?“ Hellboy). Dokonce se mi podařila stihnout zachytit i rozsvícená LEDka disku :-). Chtěl jsem původně všechny tři, ale po asi dvaceti pokusech jsem byl rád aspoň za tu jednu. Je tam vidět i jeden z webserverů, ale o těch třeba až jindy.

Takže k těm diskům. Někdy v půlce července odešel jeden z disků v poli. Díky RAIDu 5 vše běželo. Během dvou dnů IBM poslala nový a vyměnil se. Ale přecejen to bylo trochu nervoznější období, protože jak píše Terry Pratchett, jestli má něco pravděpodobnost jedna ku miliónu, můžete si být jistí, že se to stane (tedy v případě, že je to něco nepřijemného). Rozhodl jsem se proto využít jednu z funkcí, kterými se liší skutečný RAID řadič od toho, který za něj vydávají výrobci motherboardů. Přidal jsem hot-spare disk. Nyní je to ten vlevo dole.
Pro ty, kteří si nehrají se servery: jak název napovídá, jedná se o disk, který za normálních okolností „leží ladem“. Ovšem ve chvíli, kdy některý z aktivních disků vykáže chybu a je odpojen, monitoring pošle SMSku a řadič sám automatický začne pole vytvářet na tomto záložním. Rozbitý disk se pak vymění a stane se z něj hot-spare. Možná vás napadlo, co se stane ve chvíli, když by odešel během vytváření další disk. Ano, pak by přišly ke slovu zálohy 🙂 Ovšem pravděpodobnost, že během hodiny (co trvá přestavění pole) odejdou dva disky je taková, že už Pratchettovi věřit nebudu. Není to sice součin obou pravděpodobností (takže ne jedna ku miliónu na druhou :-)), ale i tak je taková, že se spíš stane něco úplně jiného.
Instalace byla také docela jednoduchá. Disk se strčil do zásuvky, přes ipssend SCANDRIVES se řadiči řeklo, že má zjistit změny (tj. přidaný disk) a pak už jen SETSTATE HSP pro nastavení stavu. Disk dvakrát zablikal jako že jo a pak už jen GETCONFIG hlásí: State: Hot spare (HSP).
